
((( ON AIR ))) DEEL 1 – In deze podcast: Erik de Gier interviewt Arjan van Hessen van Telecats en Universiteit Twente over kunstmatige intelligentie. Er wordt de afgelopen tijd veel geschreven en gesproken over kunstmatige intelligentie in klantcontact en maar al te vaak worden begrippen door elkaar gehaald of net iets verkeerd uitgelegd. Arjan van Hessen geeft duiding: Wat is waar en hoe werkt het echt?
Het is toch zelflerende software? Het wordt vanzelf beter.

Een van de meest gehoorde opmerkingen is: maar het is toch zelflerende software? We hoeven dus niets te doen en het wordt vanzelf beter! In principe is dit niet onwaar, maar….. het gaat erom wat er geleerd wordt. Iedereen met een hond weet uit ervaring dat ie zelf uitstekend kan leren, maar dat jij als baas toch echt moet zorgen dat ie het juiste leert. Let je even niet op, dan heeft de hond geleerd dat z’n eten op tafel staat, dat de bank het lekkerste plekje is om te slapen en dat je ook met modderpoten tegen iedereen kunt opspringen. Bij zelflerende software is het niet anders. Het leert wel, maar jij als eigenaar bepaalt wat de software moet doen en dus wat er geleerd gaat worden. Het idee achter zelflerende software is dat die probeert de score te maximaliseren en dus moet jij bepalen wanneer die een beloning en wanneer die straf (=negatieve beloning) krijgt.
In een contact center kan dat door bijvoorbeeld te stellen dat het gesprek goed gerouteerd werd wanneer er NIET doorverbonden werd en fout gerouteerd als er binnen zeg 10 seconden wel werd doorverbonden naar een andere medewerker. Nu de mens aangeeft wat goed en wat fout is, kan de software de beoordeelde data gebruiken om zichzelf beter te maken door bij te trainen. Ook hier gaat de vergelijking met je hond weer op: doet ie wat ie moet doen dan krijgt ie een koekje, doet ie het fout dan wordt ie genegeerd (=straf).
Wij gebruiken AI want we hebben al een tijdje een goed werkende chatbot.

Kunstmatige Intelligentie (AI) is een container begrip waar heel veel verschillende soorten software onder vallen. Ook is het begrip onderhevig aan de tijd. Iets dat 20 jaar geleden nog als AI gezien werd, wordt tegenwoordig gezien als “gewoon een slimme software” maar beslist niet als AI. Dat zal de komende jaren nog wel doorgaan, maar nu verstaan we onder AI software die geleerd heeft om op basis van gelabelde maar ongestructureerde input iets “nuttigs” te doen. Bijvoorbeeld een gesproken zin als input en een doorkiesnummer of antwoord als label.
Chatbots, software die op een gesproken/geschreven zin als invoer een antwoord formuleert, leent zich uitstekend voor een AI-benadering. Echter, bijna alle huidige chatbots gebruiken door mensen opgestelde regels om “iets” met de invoer te doen. Bijvoorbeeld als woord-X en woord-Y voorkomen dan…. Daar is niets mis mee en het kan uitstekend werken, maar het is niet een manier van processen die we tegenwoordig onder AI verstaan. Een echte AI-chatbot herschrijft eventueel de invoer (bijvoorbeeld alle meervouden naar enkelvouden of alle lidwoorden verwijderen) en gebruikt vervolgens die zin met het door mensen gegeven label om zichzelf te trainen en vervolgens aan nieuwe zinnen een juist label te geven.
Als je eenmaal een tekstuele chatbot hebt, is het eenvoudig om hem voor spraak geschikt te maken

Naarmate de spraakherkenning beter wordt, wordt de vraag om volledig gesproken chatbots op de eigen website steeds groter. Je zou denken dat, als je eenmaal een tekstuele chatbot hebt, het eenvoudig moet zijn om hem voor spraak geschikt te maken. Het antwoord hierop is ja en nee. De structuur van de dialoog kan eenvoudig hergebruikt worden en de tekstuele invoer vervangen door de resultaten van de spraakherkenner. Het antwoord geef je dan middels Tekst-to-Speech en klaar is kees. Maar….. zo eenvoudig is het niet. Het is namelijk niet zeker dat het soort vragen dat je middels spraak stelt gelijk is aan de vragen die je middels tekst stelt.
In de regel spreken mensen (niet alleen vrouwen maar ook mannen) veel meer dan noodzakelijk is om iets over te brengen. Deels komt dat doordat we nadenken over wat we willen zeggen en hoe we dat vervolgens willen formuleren. Menselijke luisteraars zijn daar, zeker in hun eigen taal, aan gewend en kunnen heel goed de minder relevante uitingen verwijderen (=vergeten) om vervolgens slechts de eigenlijke kern te “horen” en te processen. Veel uitingen in de menselijke spraak dienen om de aandacht te krijgen, de aandacht van de luisteraars vast te houden en “concurrenten” te verhinderen zelf het woord te nemen. Maar voor een spraakherkenner is dat lastig omdat die alle uitingen gewoon omzet in schrift en geen a prior beslissing neemt over wat wel of niet relevant is. De letterlijke transcriptie van een spontane discussie of vergadering is daarom dikwijls lastig om te lezen omdat alle aarzelingen, herhalingen, veranderingen halverwege de zin, letterlijk worden opgeschreven.
Het is belangrijk om gelijk oplopende trends in mijn data te vinden want dan ik er op sturen door een van die trends te beïnvloeden
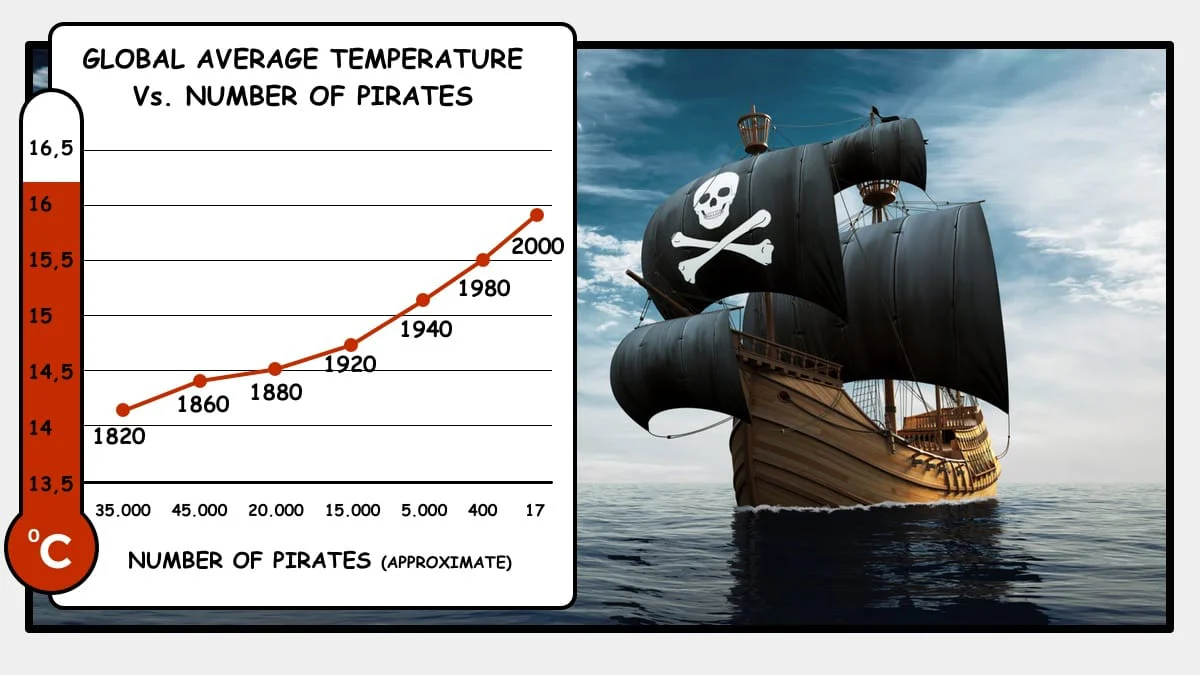
Een van de veel voorkomende verwarringen in de wereld van AI is die van Causaliteit en Correlatie. Causaliteit is het verschijnsel dat het een tot het ander leidt terwijl correlatie het verschijnsel is dat twee zaken hand-in-hand gaan. Wanneer je nu heel veel data hebt en eindeloos gaat proberen om te zien welke verschijnselen hand-in-hand of juist omgekeerd gaan, dan is de kans erg groot dat je wat vindt. Maar wat is dat dan?
Een mooi voorbeeld is de relatie tussen het afnemend aantal piraten en de stijgende gemiddelde temperatuur op aarde. Zoals uit het plaatje blijkt, is dat een bijna perfecte rechte lijn. Een ander voorbeeld is het aantal gewelddadigheden en het aantal verkochte ijsjes. Met een beetje filosoferen kun je voor beide voorbeelden best een achterliggende verklaring vinden, maar het aantal gewelddadigheden stijgt niet omdat het aantal verkochte ijsjes stijgt.
In de wereld van AI en Data Science zijn dit veel voorkomende misverstanden: niet van de kant van de onderzoekers maar vooral van de opdrachtgevers. Die willen dikwijls een causaal verband vinden omdat je daarmee de zaak kunt sturen.
Binnenkort verloopt het klantcontact via praatpalen

In Nederland zal, net als in de USA, het percentage huishoudens dat een praatpaal heeft binnen een paar jaar de 30% overschrijden. Praatpalen zijn Hot en talloze bedrijven zijn er mee aan het experimenteren. Hoe kunnen klanten direct met hen praten zonder tussenkomst van de klantenservice?
Klinkt mooi en de demo’s zijn interessant en vooral leuk maar relevante zaken blijven onderbelicht. Hoe ga je de privacy garanderen? Hoe ga je om met de openbaarheid van de dialoog? Hoe ga je de identificatie doen? De eerste Nederlandse demo’s richten zich op het opvragen van informatie en deze oplossingen zullen in eerste instantie vooral de reeds bestaande selfservice oplossingen online of in Apps gedeeltelijk vervangen. Maar ook voor de informatieverstrekking is het de vraag of je die alleen in gesproken vorm wilt hebben. Wellicht dat de nieuwe Praatpalen met scherm een betere oplossing zijn om de gevraagde informatie tot je te nemen.
AI gaat alle medewerkers in klantcontact vervangen

Een veel gehoorde angstkreet van veel mensen uit de branche, maar is dat ook zo? Niemand die het weet, maar wat wel zeker is, is dat een steeds groter deel van het huidige werk door steeds slimmere algoritmes zal worden overgenomen. Er kan dan gekozen worden om het serviceniveau te handhaven op het huidige peil en het zelfde werk met steeds minder mensen te doen. Of men kan besluiten om het serviceniveau naar een steeds hoger plan te duwen. En daar heb je dan (voorlopig) weer veel mensen voor nodig.
De toekomst voorspellen blijft lastig, maar je zult zien dat AI een steeds grotere rol zal gaan spelen. En in eerste instantie zal dat gebeuren als assistent van de medewerker: de vraag herkennen, mogelijke antwoorden snel opzoeken en aan de medewerker presenteren die dan, gegeven de context van het gesprek, het juiste antwoord zal selecteren.
Tot slot
Een deel van de verwarring over kunstmatige intelligentie komt voort uit de sterke focus op technologie: wat kan die technologie straks allemaal en hoe gaat ons leven er dan uitzien. Onder andere Judith Flanders en Tom Vanderbilt hebben daar behartenswaardige dingen over geschreven. Flanders beweert dat futurologen bijna altijd focussen op de veranderingen door c.q. van de techniek en niet op de veranderingen die die technologie heeft op onze manier van samenleven. Daarom komen veel voorspellingen niet of slechts gedeeltelijk uit. Men gaat ervan uit dat ons leven door blijft gaan zoals het nu is en focust zich alleen op de verandering van de techniek. Maar de techniek heeft een enorme invloed op onze manier van samenleven en die verandering is wellicht groter dan de techniek sec.
“Futurologie is bijna altijd verkeerd omdat het zelden rekening houdt met gedragsveranderingen. We kijken naar de verkeerde (=technische) dingen: “Transport naar het werk, in plaats van de vorm van het werk en hoe ons gedrag verandert door de veranderingen die de technologie met zich meebrengt”. Het blijkt dat het moeilijker is om te voorspellen wie we zullen zijn dan om te voorspellen wat we zullen (kunnen) doen.” Historica Judith Flanders
